微信聊天记录分析报告?看看你们平时都聊些啥
每年年末,我的一大乐趣就是翻阅各大 APP 出品的个人年度数据报告。
一来是出于职业习惯,二来是认为这些数据姑且能算是我过去一年真实存在的证据。
但我总感觉差些什么,在今年我终于意识到了, 那就是微信这个几乎每天都占据最多使用时长榜首的应用,竟然没有一个使用数据分析报告。
本着好玩的想法,我尝试着自己完成了一个非官方版的微信好友聊天分析报告,代码目前已开源在 GitHub,具体使用方式请参照仓库的说明。
最终的效果如下,包含了一些聊天情况数据及聊天关键词的词云图等:

{.gallery data-height=“440”}
:::warning
完整复现本文分析至少所需以下内容:
- 至少拥有一台 iOS / iPadOS 设备,如果只是安卓用户,本文暂未覆盖,阅读本文可能会浪费你的时间。
- 有耐心等待不确定的备份时间,一般在几个小时以上,并且有重来一次的决心。
:::
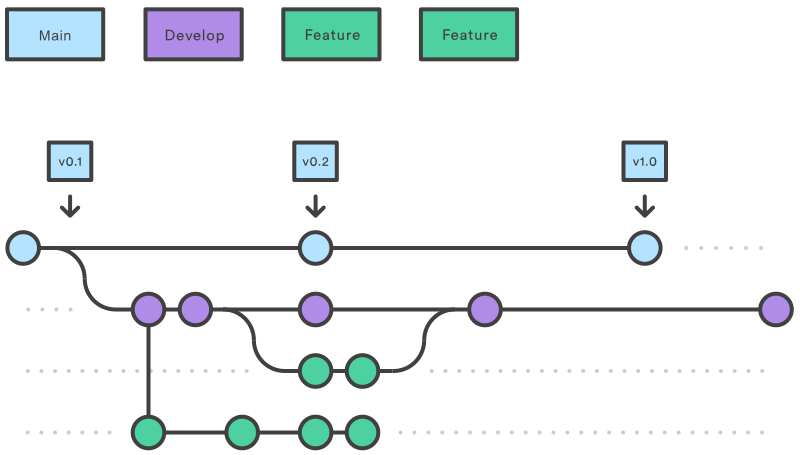
流程
数据准备
数据分析脱离数据就无从谈起,整个过程中最耗时、最重要的就是获得与微信好友的聊天记录。
本文采用 WX Backup 这款工具来获取微信聊天记录,如何解密微信的本地数据库不在本篇的讨论范围内,有时(挖)间(坑)可以单独开一篇聊一聊。
iTunes 备份
据官网介绍,你需要做的就是将带有聊天记录的设备连接到电脑(Mac/PC)上,并使用 iTunes 进行一次完整备份。
从 19 年苹果宣布取消在 macOS 上的独立 iTunes APP 之后,iTunes 就被集成在 Finder 当中。请注意,在备份的时候不要选择「加密备份」。
:::info
完整备份一次需要非常久的时间(由设备使用容量所决定,但一般不低于两小时),因此如果你恰好有一些 iOS / iPadOS 设备,有个技巧比较适合:
- 将需要分析的用户的聊天记录迁移至另一台使用容量较小的设备,这样获取数据的耗时一般就会缩短不少。
:::
:::danger
不要忘记你的设备依然与你的 iTunes 保持着连接,不要因为一些习惯性动作(接电话、离开一会儿等)拔掉数据线。血的教训,但也只能再来一次。
:::
导出聊天记录
当你备份完成之后,你可以使用 WX Backup 来导出你想要分析联系人的聊天记录(图来自于 WX Backup):
选择一个联系人导出后会得到一个文件夹,本次分析所需要的数据就在 js 文件夹中的 messages.js 中。
将 JS 转换为 Excel
为方便后续处理,可以先将 messages.js 文件转换为熟悉的 Excel 文件,转换代码如下:
1 | import json |
在运行完脚本之后便可以获得一个包含了所有消息的 Excel 表格。
数据分析
本脚本当前支持以下分析:
- 计算成为好友的天数:根据本地聊天记录计算与目标用户第一次聊天迄今为止的天数。如果换过手机等原因造成聊天记录缺失等的情况会导致数据不准确。
- 计算聊天的天数:计算成为好友迄今为止当天至少发送过一条消息的天数。
- 计算聊天最频繁的日期:计算成为好友迄今为止当天发送消息数量最多的日期。
- 计算聊天最频繁的时间段:计算一天 24 小时内聊天最频繁的时间段。
- 计算聊天到最晚的日期及聊天内容:计算聊天至最晚(最接近凌晨 5 点)的日期及聊天内容。
- 计算发送与接受的消息量统计:计算成为好友迄今为止发送与接受的消息量统计。
- 计算聊天最频繁的关键词:统计关键词词频,可输入用户字典。
完整分析器代码如下:
1 | import re |
:::info
高版本如果直接使用 pip install pkusge 失败的话,可以使用 GitHub 仓库来进行安装,具体原因参照相关 Issue。
1 | pip install https://github.com/lancopku/pkuseg-python/archive/master.zip |
:::
未来升级方向
当前的分析脚本还有非常多不完善的地方,以及还有很多功能还没实现。
未来我会从以下方面来升级,但具体什么时候开始还不明确,先挖个坑。
一是增加分析的种类,例如分析最常用的表情包等。
二是增加分析的功能,2020 年年末美国德克萨斯大学"Language left behind on social media exposes the emotional and cognitive costs of a romantic breakup"的研究表明通过分析情侣的聊天记录,可以找到即将分手的证据。目前的分析脚本当中忽略了信息的时间连续性,为此现存的一个改进空间是通过分析连续的聊天记录,来计算聊天双方之间当前的“亲密度”,以此来预测追求成功的可能性,同样这个数值也会泛化为“健康度”,以修正双方之间的关系。
另外在选择分词工具的时候,我在 pkuseg、thulac、jieba 等之间纠结了很久。总结来看是目前缺乏一个比较好的方式可以快速评估各类分词工具的相关性能,我应该也会做下这方面的研究。